Monitoring
U zákazníka jsme měli nasazené řešení (sestávající se z několika málo desítek komponent), ke kterému jsme poskytovali second level support. Selhání byť jediné komponenty mohlo způsobit zastavení celé produkce. Identifikace toho, která komponenta zapříčinila výpadek, bylo zbytečně zdlouhavé. Nehledě k tomu, že jsme nedokázali problémy dostatečně předvídat. Zákazník zcela logicky začal požadovat monitoring celého řešení.
Velkou část minulého roku jsem tak strávil s monitoringem. Nepovažuji se v dané problematice za odborníka (podle kompetenční matice bych to viděl tak na n2), ale minimálně si chci napsat pár poznámek pro sebe, abych vše nezapomněl. Měl jsem zahrnout monitorování do Joel Test 2.0, protože si dnes už nedokážu představit provozovat komplexní systém bez monitoringu.
Chci se nejprve obecně věnovat problematice monitoringu a pak konkrétní implementaci a to Nagios, respektive Eyes of Network, které nad Nagiosem staví.
Úvod do monitorování
Co to je monitoring? Z mého pohledu jde o sledování a hlášení kritických chyb, nebo ještě lépe včasné varování, pokud se nějaká chyba blíží. Mezi základní kritéria si můžete představit volné místo na disku či operační paměti, čas do vypršení certifikátu, ping, telnet… Představivosti se meze nekladou. Mám vyzkoušené, že analýza toho, co monitorovat a jaký nastavit threshold (práh, hranice) zabere mnohem víc času než samotná implementace, která je v podstatě jednoduchá. Platí, že měření by nemělo ovlivnit měření či v lékařské terminologii vyjádřeno primum non nocere (především neškodit).
Technologie
U samotného výběru technologie jsem nebyl, šlo o politické rozhodnutí, ale myslím, že (zpětně viděno) šlo o dobré rozhodnutí. Byla vybrána technologie Eyes Of Network (dále jen EoN) postavená na technologii Nagios, která je de facto průmyslovým standardem. Jedná se o open-source řešení (pod licencí GPL2, se kterou ovšem můžete někde v komerční sféře mít problémy, ale neměli byste, protože k EoN budete nejspíš přistupovat jen jako k black-box). Distribuované jako CentOS image. Projekt sponzoruje firma APX, u které si můžete objednat konzultanty. Jediná nevýhoda je, že je to francouzský kód, takže občas na mě v logu nebo některých návodech vykoukla francouzština.
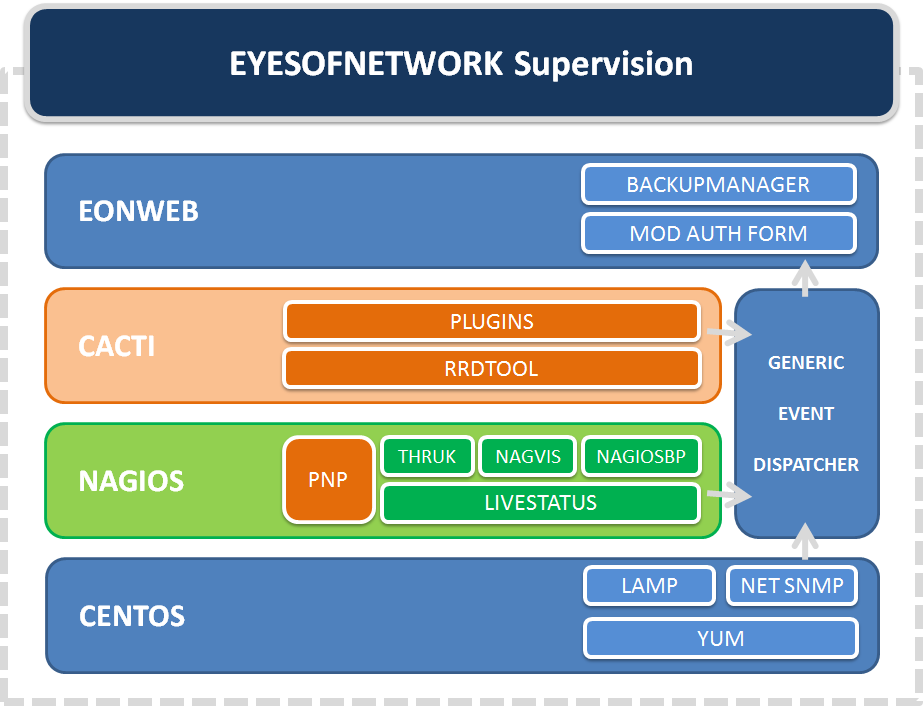
Architektura Eyes of Nework, zdroj: www.eyesofnetwork.com
Nagios
Pár termínů, se kterými se setkáte v Nagiosu. Host je cokoliv, s čím se domluvíte přes TCP. Service je logická entita, která běží na hostu (pozor, nezaměňovat za windows service).
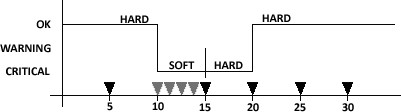
Hard/soft state, zdroj: JBsWiki (cc-by-sa 3.0)
Nagios rozlišuje tzv. hard a soft state. Jde o to, že když se zatoulá jeden ping, tak aby vás to zbytečně neděsilo či dokonce nebudilo. Indikuje-li se chyba, výrazně se zkrátí interval kontroly a teprve když se chyba potvrdí, přepne se do hard state.
SNMP
SNMP (Simple Network Management Protocol) je protokol pro správu sítí, ale my ho můžeme využít i pro monitoring, aniž bychom museli instalovat nějaké agenty (o nich později). Můžete tak monitorovat třeba místo na disku, volnou operační paměť…
Potřebujete, aby vám na monitorovaném stroji běžela windows služba SNMP (pokud ne, musíte si featuru přidat). Službu si musíte nastavit. Bude vás zajímat především community name, stačí přístup READ ONLY. Dobré omezit na IP adresu monitorovacího serveru. Ano vím, lze podvrhnout, ale jednak jsme zapnuli READ ONLY režim a jednak doufám, že vaše síť má ochranu proti ARP poisoning. Každopádně vyšší verze SNMP už umí i TLS (nezkoušel jsem).
Lokální Pluginy
Pro Nagios existuje kvanta pluginů, takže dost možná nebudete muset psát žádný vlastní. Ale i kdyby, tak psát vlastní Nagios plugin je triviální. Můžete použít libovolný programovací či skriptovací jazyk, vystačíte si s pár status kódy a formátováním textu. Ty již hotové jsou často Perlu, ale když pluginy pouze spouštíte, tak vás to nemusí děsit. To jen připomínka, kdybyste se v nich chtěli vrtat.
Namátkou jmenujme pár, se kterými se nejspíš setkáte. Předně check_snmp je potřeba pro monitorování SNMP (podrobnosti viz výše). S pluginem check_http můžete kontrolovat HTTP status kódy, (ne)přítomnost konkrétního textu, platnost certifikátů… Pro monitorování Oracle databáze slouží check_oracle_health. Pozornosti javistů by neměl uniknout plugin check_jmx.
Vzdálené pluginy
Předchozí pluginy se volají přímo z monitorovacího serveru. Můžete ovšem potřebovat kontrolovat něco lokálně na daném hostu, ať už kvůli tomu, že potřebujete přímý přístup na systém či daný protokol neproleze firewallem.
K tomu slouží NRPE (Nagios Remote Plugin Executor), protokol založený na TCP/IP. Pomocí pluginu check_nrpe provoláte na hostu agenta.
NSCLIENT
Nejznámější agentem je NSClient++ pro operační systémy MS Windows. Díky němu můžete volat VB skripty, BAT, EXE a v neposlední řadě PowerShell.
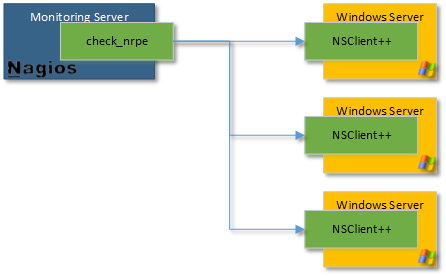
zdroj: nsclient.org
JNRPE
Existuje i Java klient JNRPE. Pokud implementujete vlastní plugin v Javě (návod bohužel zmizel!), tak se s každý checkem nespouští separátní JVM.
Nagvis
Díky Nagvis, který je součástí EoN, si můžete monitorovanou platformu vhodně vizualizovat. Jako pozadí si vyberete libovolný obrázek a pak nataháte bubliny, které reprezentují jednotlivé service nebo host.
zdroj: nagvis.org
Zkušenosti
EoN podporuje šablony (template), takže je dobré je využívat, abyste si ušetřili práci. Lze tak nadefinovat třeba šablonu pro Windows host, která bude zahrnovat kontrolu rozhraní (např. Hyper-V), ping, disku a operační paměti. To se bude kontrolovat na každém hostu, ale přidáte si specifické kontroly pro daný host a jednotlivé service.
Kde se musí monitoring autentizovat, je kvůli bezpečnosti potřeba použít speciálního uživatele s omezenými právy. Ukázka pro databázi Oracle.
Dost se mi osvědčil PowerShell. Ne že bych skripty raději nepsal v Groovy, ale PowerShell je v podstatě na každé windows mašině.
Co jsme v první fázi neřešili, protože bychom na tom analyticky strávili dost času, jsou notifikace a eskalace. Systém může posílat třeba SMS nebo e-maily, přičemž pokud ten, kdo drží službu, neopraví chybu do nějaké doby, tak se upozorní například jeho nadřízený. Zase je to víc o byznys procesech.
Škálování bych se nebál. Naše nasazení mělo řádově stovky kontrol. Ale chlapci z APX tvrdili, že (jestli si dobře pamatuji), v Airbus továrně na vrtulníky mají 20 tisíc kontrol.
Závěr
Pokud pouze nedodáváte hotové řešení, ale rovněž ho i provozujete, rozhodně bych po nějakém, byť minimálním monitoringu sáhnul. Za sebe můžu říct, že Nagios v podání Eyes of Network byla dobrá volba a že i placená podpora od APX v případě složitějšího systému stojí za zvážení.
Edit
Martin Stiborský mě na twitteru upozornil na Incinga, jedná se o fork Nagiosu. Podle dema vypadá pěkně a responzivně (hlavně ve srovnání s EoN). Při nějakém dalším monitoringu určitě zvážím, GUI mě nalákalo a téměř vše výše řečené tam bude platit taky.
There was a 'Moved Permanently' error fetching URL: 'https://twitter.com/stibi/status/834873330700333058'
