Finta s cache na více nodech

Jeden z klamů, kterému stále podléhám, je, že vám program poběží v jediné instanci. Jasně, mnohdy na to myslím, klasicky zajištění, aby úloha v celém clusteru běžela maximálně právě jednou, k tomu perfektně slouží knihovna ShedLock. Nicméně pro některé případy stále ještě nemám vypěstovanou dostatečnou intuici. Fousatá legenda praví, že v IT máme dva obtížné problémy: pojmenování věcí a invalidaci cache. No a jak invalidovat cache pro více nodů? Distribuovaná cache. Tak to nechceš. Pro svůj případ jsem našel jednodušší funkční řešení.
Úvod
Moje práce je v současné době z větší části open-source, takže bych vás mohl odkázat rovnou na konkrétní pull request, ale asi vám bude chybět kontext dané komponenty a taky principy použitého API. Cache v tomto případě nepoužíváme pouze pro databázové dotazy, ale pro sestavení klienta pro posílání push notifikací (je to náročné na zdroje kvůli práci s certifikáty). Když v admin API změním konfiguraci, invaliduji cache. Jenže to platí jen v případě, kdy provozujeme jedinou instanci. Pakliže máme instancí více, ostatní se o změně nedozví. Distribuovanou cache jsem nechtěl zavádět, jelikož řešení můžeme provozovat my i zákazníci sami (a čím méně toho musí nastavovat, tím lépe). Teoreticky by si ještě instance mohly posílat zprávy, ale ideálně by o sobě vůbec neměly vědět.
Caffeine CacheLoader
Pro jednoduché použití existuje osvědčená knihovna Caffeine, kterou už jsme na daný případ používali.
Zkoumal jsem tedy podrobněji API, čeho můžu dosáhnout.
Našel jsem funkcionalitu refresh, kterou realizuje CacheLoader pomocí metody #reload(K,V)
Přiznávám, že jsem trochu empirický programátor, kouknu na název metody a proletím JavaDoc, ale reload funguje trochu jinak, než jsem na první pohled čekal.
Vlastně nakonec dokonce lépe (byť to má svoje specifika) a tak jak dokumentace podrobně popisuje.
Možná jste tedy rychleji než já pochopili, jak to celé funguje, ale pokud byste měli zájem i o vysvětleními mými slovy, tak čtěte dále.
Nastavení refreshAfterWrite=5m totiž není tak tupé, že každých pět minut nahrává hodnotu znovu, ale po pěti minutách je záznam vhodný na refresh.
Přičemž refresh se odpálí teprve až dotazem na daný klíč (co kdybyste danou hodnotu používali třeba jen jednou denně).
A aby nedošlo ke zdržení, tak vrátí starou hodnotu a asynchronně si dopočítá novou (v našem případě ještě kontrolujeme timestamp změny, zda je to vůbec potřeba).
Projevení změny v databázi (způsobené jiným nodem) je tedy o takt zpožděné.
Při editaci ze stejného nodu refresh vyvoláváme rovnou (tam logiku zachováváme, respektive vylepšujeme; předtím tam byl evict, který záznam smazal, teď ho rovnou předpočítáme).
Zasloužilo by si to diagram, že?
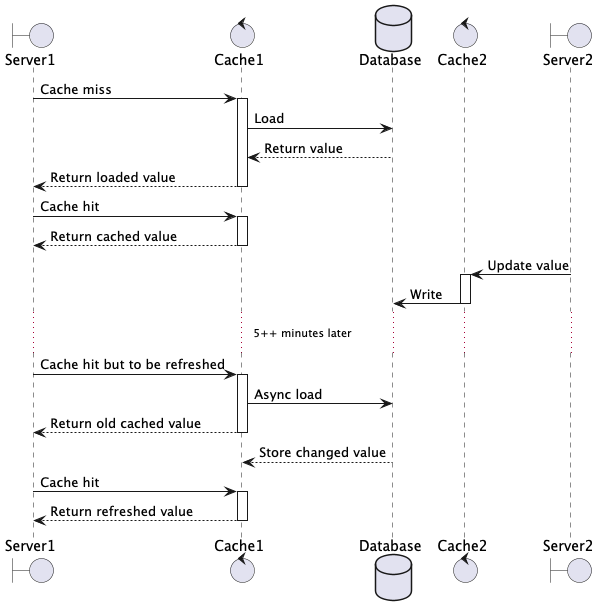
Závěr
Programátor by měl pořád myslet na to, co se stane v produkci. Lokálně si spouštíte jedinou instanci a tak to vždycky být nemusí, spíš to tak nikdy ani nebude. Ukázali jsme si, jak lze invalidaci cache mezi více nody obejít i bez distribuované cache nebo posílání zpráv.
